
The Elephant in the Dark: Imagine a group of blind men tasked with describing an elephant. Each touches a different part - the trunk, the tusk, the leg - and forms their own unique understanding. This is what happens in organizations without data catalogs. Different departments, unaware of the whole picture, have fragmented views of the data, leading to inconsistencies, inefficiencies, and missed opportunities.
Much like the blind men attempting to describe an elephant based on the limited information from their touch, organizations without a robust data catalog may find themselves grappling with incomplete perspectives of their data landscape. Without a centralized repository for data knowledge, different departments or individuals may interpret data in isolation, leading to fragmented insights and decision-making. This metaphor perfectly illustrates the challenge of understanding and utilizing data assets efficiently without a data catalog. In today's dynamic data landscape, where data volumes and sources explode, organizations require a holistic view to truly harness the power of their information.
Consider a scenario where bookings and revenue data are scattered across diverse data hubs. The marketing team, analyzing bookings from their hub, might see a rising trend. Simultaneously, the finance team, looking at their revenue hub, might paint a different picture. Siloed departments, using disparate systems, hold fragmented views of the data, leading to:
Inconsistent KPIs and metrics: The blind men each describe their elephant differently. Similarly, revenue data across different departments might vary, creating confusion and inaccuracies in revenue calculations. For example, the marketing team might track bookings through leads, while sales use closed deals, leading to discrepancies in reported figures.
Missed Opportunities: Each blind man misses valuable information about the elephant. Without a data catalog, teams might miss crucial insights hidden within the data, hindering their ability to make informed decisions and optimize operations. Imagine a customer service team unaware of purchase history, hindering personalized service and upselling opportunities.
Duplication of Efforts: The blind men waste time describing what others already know. Similarly, teams might unknowingly duplicate efforts due to data fragmentation. For instance, both finance and marketing might collect customer data, leading to redundant data entry and wasted resources.
Why Data Cataloging is Indispensable
In today's dynamic business landscape, reliable and accessible data is crucial for informed decision-making and adaptation. A data catalog acts as a central repository, organizing and illuminating your organization's data assets. It's like a library card catalog for your data, allowing everyone to find what they need and understand its context, regardless of their technical expertise.
Data Democratization: Everyone from analysts to business users can readily discover, understand, and trust data, fostering data-driven decision-making across all levels.
Improved Data Governance: Define and enforce data quality standards, lineage, and security, ensuring compliance and mitigating risks.
Collaboration and Trust: Share knowledge about data assets effortlessly, breaking down silos and fostering collaboration among data stewards and consumers.
Enhanced Efficiency: Reduce time spent searching for and validating data, freeing up resources for analysis and innovation.
Proactive Insights: Anticipate data-related issues and opportunities through automated alerts and notifications.
Why is a Data Catalog Critical?
Some interesting facts to illustrate the importance:
Data chaos is real: A study by Experian found that 60% of business data goes unused due to lack of discoverability and understanding.
Blindfolded decision-making is costly: Poor data quality costs US businesses an estimated $3 trillion annually, according to Gartner.
Time is money, and data confusion wastes it: Employees spend an average of 14% of their time searching for and understanding data, according to IDC.
Real-life examples:
A retail company struggled with inconsistent product descriptions across different platforms, leading to customer confusion and lost sales. A data catalog helped them identify and standardize product information, resulting in a 20% increase in conversion rates.
A pharmaceutical company faced delays in drug development due to difficulty tracking data lineage and ensuring data quality. A data catalog improved data transparency and traceability, reducing development time by 30%.
A financial services company lacked a clear understanding of customer data, hindering personalized marketing campaigns. A data catalog enabled them to segment customers effectively, leading to a 40% increase in campaign engagement.
Implementing a data catalog doesn't have to be an elephantine task:
Start small: Focus on capturing basic metadata for high-impact datasets first.
Involve stakeholders: Get buy-in from business users and technical teams for long-term success.
Embrace automation: Leverage tools to automate data ingestion, metadata extraction, and data quality checks.
Make it user-friendly: Ensure the data catalog is intuitive and searchable for everyone, regardless of their technical expertise.
20 Essential Steps for Effective Data Cataloging
Define Your Goals: Align the catalog with organizational objectives to focus efforts on valuable data assets.
Identify Data Sources: Inventory all data sources, structured and unstructured, across your organization.
Gather Metadata: Collect meaningful metadata about each data asset, including lineage, description, owner, usage statistics, etc.
Data Quality Assessment: Evaluate data quality and cleanse inconsistencies to ensure reliable analysis.
Standardization: Establish consistent naming conventions, data types, and formatting for accurate retrieval.
Business Glossary: Define business terms associated with data assets to bridge the technical-business gap.
User Roles and Permissions: Assign access controls based on user roles and responsibilities to maintain data security.
Integration with Analytics Tools: Seamlessly connect the catalog with analysis tools for streamlined workflows.
Collaboration Features: Facilitate communication and knowledge sharing around data assets.
Regular Updates: Continuously refine and update the catalog as data environments evolve.
Data Lineage Tracking: Map the origin and transformation of data for transparency and traceability.
Data Discovery: Allow users to search and discover relevant data assets through powerful search functions.
Data Quality Monitoring: Implement automated checks to monitor data quality and identify potential issues.
Data Privacy Compliance: Ensure adherence to data privacy regulations and maintain data subject rights.
Change Management: Implement strategies to educate and onboard users on the data catalog.
Governance Policies: Establish data governance policies and enforce them through the catalog.
Data Ownership: Clearly define data ownership to ensure accountability and stewardship.
Security Measures: Implement robust security measures to protect sensitive data assets.
Performance Optimization: Optimize the catalog's performance for scalability and responsiveness.
Analytics for Continuous Improvement: Leverage usage data to understand user needs and improve the catalog.
Data Catalog Items for Comprehensive Coverage
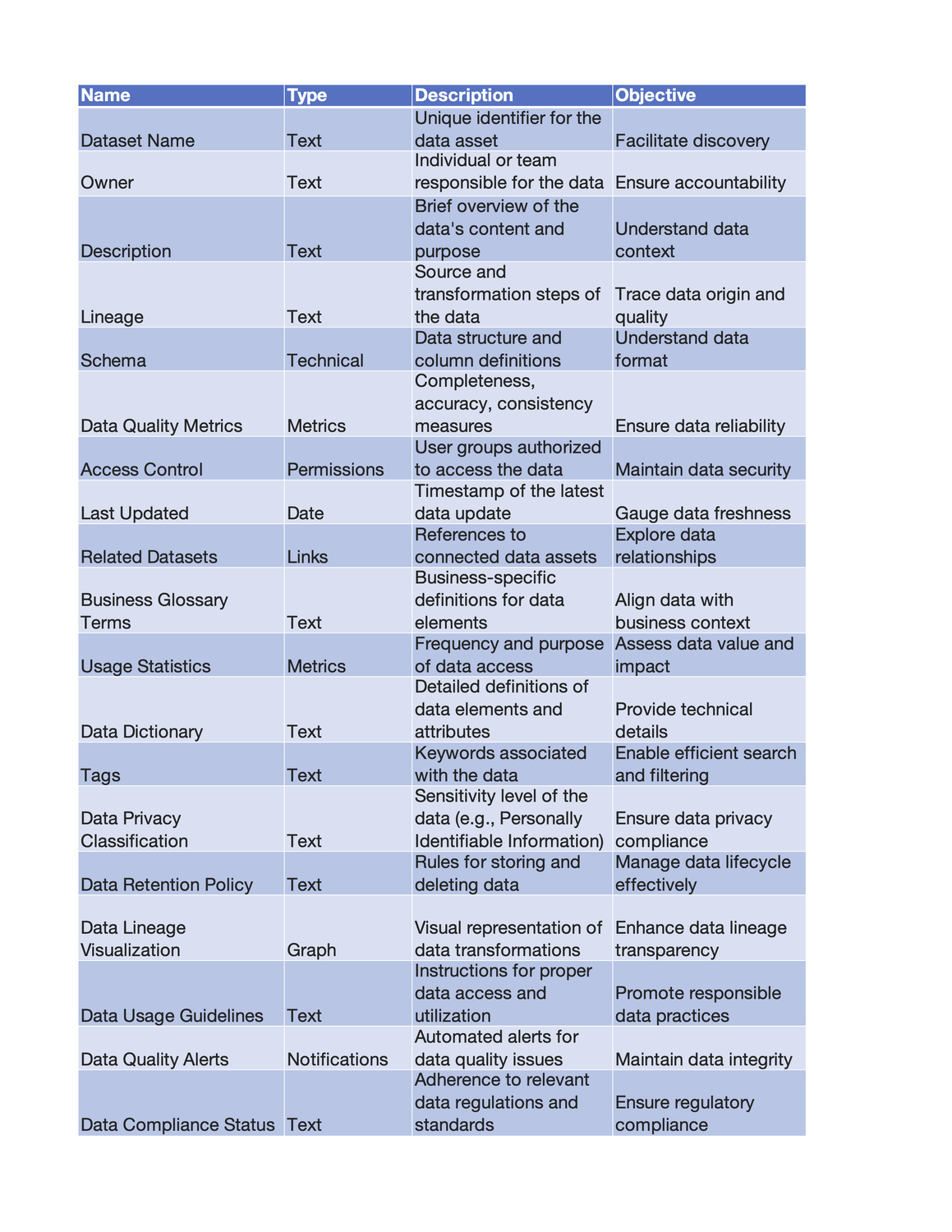 Data Catalog Items
Data Catalog ItemsTools and Utilities for Data Cataloging:
Here are some tools and utilities, along with helpful GitHub repositories, for creating a data catalog using Python:
Open-source options:
Metaflow: A Python library for building and managing data pipelines, which includes data catalog functionality. Its strength lies in its ability to automatically capture lineage and dependencies. (https://github.com/Netflix/metaflow)
Amundsen: An open-source, modular data catalog built on Apache Airflow. It offers a flexible and scalable solution with multiple deployment options. (https://github.com/amundsen-io)
Carte: A Python library for generating static data catalog sites. It scrapes metadata from data sources and creates a searchable HTML frontend. (https://github.com/topics/data-catalog)
Datahub: An open-source metadata platform that focuses on governance and collaboration. It allows you to define and manage data ownership, access control, and usage statistics. (https://datahubproject.io/)
Luigi: A Python workflow management library that can be used to create data pipelines and automatically track their lineage. It integrates with tools like Airflow and can be used to populate a data catalog. (https://pypi.org/project/luigi/)
Commercial options:
Collibra Data Catalog: A comprehensive data catalog with advanced features like data quality monitoring, compliance management, and data governance.
Informatica Cloud Data Catalog: A cloud-based data catalog that leverages machine learning for automated data discovery and classification.
Alteryx Data Catalog: A data catalog integrated with the Alteryx analytics platform, providing seamless data governance and discovery within the platform.
Additional resources:
Awesome Data Management: A curated list of open-source tools and commercial products for data management, including data catalogs. (https://github.com/awesome-mlops/awesome-data-management)
data-tools: A GitHub topic focusing on various data tools, including Python libraries for data cataloging. (https://github.com/topics/data-tools)